When building a new app or feature, it can be tempting to immediately start with “import framework” and then build from there. First search for the latest and greatest toolchain, and then get building. It’s best practice, right?
Before we do that, we always first have a look at how much time it would take to write the feature we need. Could we get away without adding another framework with all its dependencies? If the feature seems simple enough, we choose to write a version of it ourselves first.
Using a framework (and libraries to a smaller extent) is always a trade off. There are plenty of examples of both extremes of course. We’ve all seen those websites which load jQuery, Vue, React, Bootstrap and Tailwind, because the entire thing is just dependencies duct taped together. Or introducing a dependency for 11 lines of code, like left pad. On the other hand there are examples of “Not invented here” going so far that products become insecure because they ignore all the hard work done before them (e.g. don’t roll your own crypto, as the advice goes).
The benefits of frameworks are obvious. Everything it already does right you don’t need to work on. And when building an MVP (or feature in any stage of your startup for that matter) you need every minute you can save. So what are the costs we look at? The most obvious is that all those lines of code will eat RAM and CPU (and GPU these days), so if there are large parts you don’t need, that would be wasteful. But there are many other costs too:
- Learning new concepts. Many frameworks usually lead to a rabbit hole of new concepts you need to explore, very specific to just that framework. Read the docs, explore some tutorials, find out what the “framework way of doing things” is. That includes dependencies on which the framework in turn relies on.
- Maintenance. You need to keep up with at least security updates, so you need a system in place to learn about those and apply them in time. Ideally you could keep your code running for years and just apply some security updates. But typically the older a dependency gets, the bigger the chance is there won’t be updates for the “old” version, and you need to upgrade to a new version with lots of API changes. So even though your code itself still works perfectly, there’s some bitrot going on, and you need to keep updating your code. You might even have to start over learning new concepts for the new version. Another problem is you need to make sure those (security) updates and in turn all its dependencies can be trusted, which isn’t always easy to do.
- Unexpected behavior & debugging. With large frameworks there’s always a risk some internal implementation “detail” isn’t really documented well, but is actually important to understand in order for your app to work right. Often you only find this out the hard way after running into a bug. Debugging large frameworks, just like any other codebases you’ve never worked on, can be really time-consuming with deep call stacks and dozens of files.
- Unknown constraints. Another big risk is finding out half-way that the framework doesn’t really support your use case. Or it simply doesn’t scale.
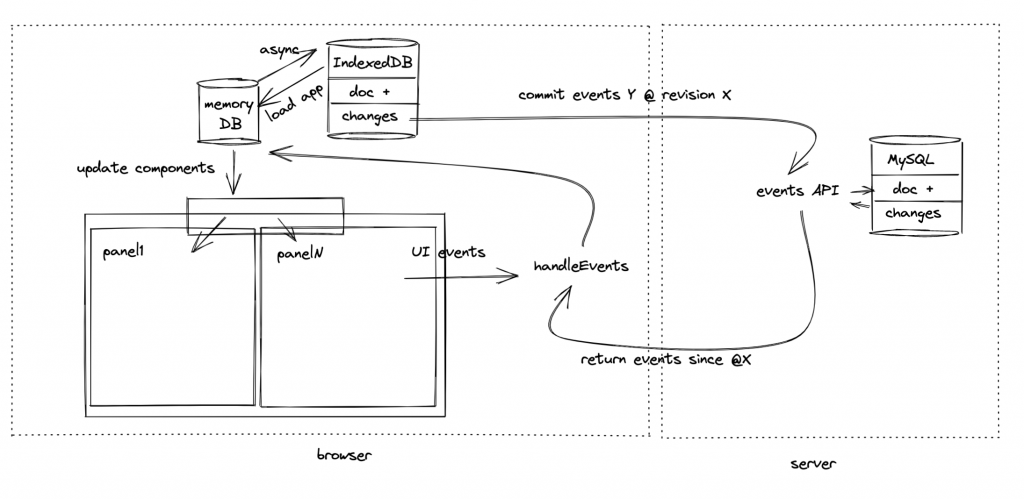
For example, one of the features we’re working on for Thymer is real-time collaboration features using Websockets. Because our backend is Django (a framework which definitely saves us time!), I googled around and found out there’s a project called Django Channels, which extends Django beyond HTTP, including Websockets.
Again, it would sound tempting to simply start there, just import it and done. In this case we would already have to start out with quite a number of new concepts to explore, or new layers we have to add to the stack: ASGI and asgiref, Daphne server, Redis, interfacing with synchronous Django code. Some of those we had never heard of or worked with before. And that’s next to the API of the framework itself, and finding out whether it works for the purpose we need. I’m not at all implying Django Channels isn’t a great framework! The point is that using a framework has a cost, just like writing it yourself does, so we need to compare the two.
So let’s look at what we really need in terms of Websocket functionality. We need to accept connections, keep track of open connections, be able to query the database using Django’s ORM and finally inform open connections when a new event becomes available for them. That’s it. Looking at all this, it’s not completely obvious the integration Django Channels provides with Django is worth the costs (new concepts, add layers to the stack, maintenance, debugging, knowing we don’t run into unknown behavior).
In this case we made the decision to write a simple Websocket script ourselves. It turned out to be around 200 lines of Python3 code and it took 1 day to build.
That would certainly not have been faster when having to look into all the ins and outs of the framework, and even without a deadline of 80 days we’d want to get an MVP out as soon as possible. If we have many customers at some point and it turns out we need something more advanced, then we can still look into rebuilding it (because it’s just 200 lines after all!). And best case 10 years from now this simple script will still be running, happily serving customers, without any modifications. Which is exactly what happened to our websocket script for our first product.