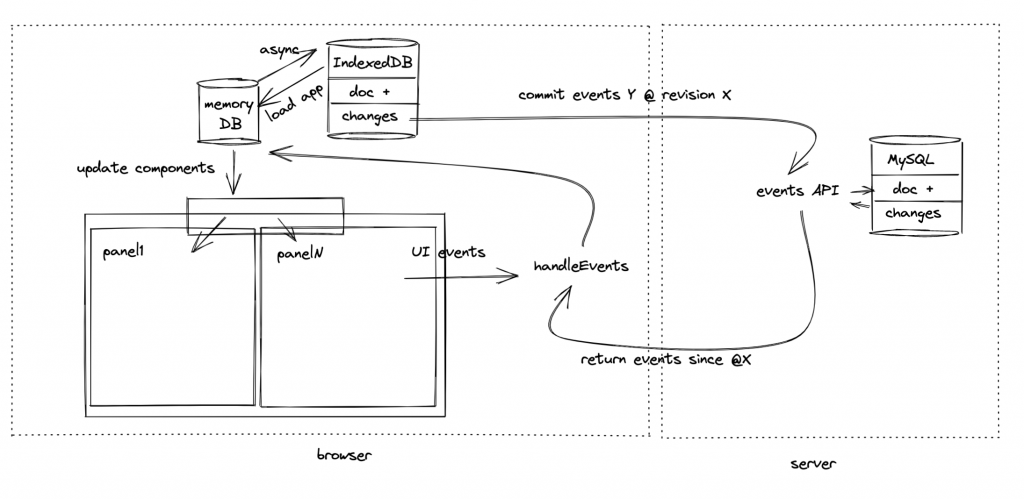
Friday Wim wrote about Data and Event Handling on the client side of Thymer.com. Today is about our approach to data storage on the server side. All storage, with very few exceptions, will go directly into a SQL database. MySQL is what we know best, so that’s what we’ll use.
Almost all of our database tables will have at least these columns:
- “id” (unique auto increment primary key),
- “guid” (unique, user facing),
- “group-id” (integer foreign key),
- “created-at” (datetime),
- “updated-at” (datetime),
- “deleted-at” (datetime, nullable),
- “destroyed-at” (datetime, nullable),
- “extra_json” (plain text)
I’ll explain briefly what our reasoning is for having these columns.
GUID with unique index + auto-increment int primary key
Having auto-increment primary keys for internal use is convenient, but exposing these keys to the outside world isn’t great. It’s better to use GUIDs in the (JSON) API. Integer primary keys are considerably faster, though, so you can use use both. That’s what we’re doing. A side benefit is that you can use the GUIDs for backup and export/import purposes. You can’t easily import data with auto-increment keys, because you’ll get key collisions, but you don’t have this difficulty when you use GUIDs. They don’t collide by design. If you ever have to shard your service, or want to move data between SQL servers for another reason having GUIDs to work with will save you a great deal of time.
It also makes for much friendlier APIs. You can prefix the GUIDs with the class table it corresponds to. If the wrong kind of GUID is passed to the API, for instance “user_56b2c555-1ccf-4b9a” instead of “project_854a3923-0be9-4106” you can generate a friendly error message that the API function expected a Project instance instead of a User. If you just pass a generic integer you have to return a confusing error message about insufficient permissions because you can’t determine what the API users is trying to do.
Redundant group-id columns
Suppose your product allows groups of users to collaborate and you don’t want to accidently mix up information between groups. You don’t want to put yourself in a situation where users see other people’s data just because you forget a “WHERE” clause in an SQL statement somewhere. Mistakes are unavoidable, but some mistakes are unacceptable and we plan to design our system so the worst kind of mistakes can’t happen. If all tables have a group column (or equivalent) then you can enforce through your ORM that all queries are automatically filtered for access. You can make all database queries go through a single point that ensures a user of Group A can only see data from Group A.
A side benefit of storing redundant group information is that it makes for very easy clean up when people want to close their account. You just go through all database tables and you drop all records for that user/group. If you have to infer which data belongs to which user through foreign keys you can create a difficult situation for yourself. Especially when you need to delete a lot of data you want to be able to do so incrementally. You don’t want your service to become slow (or crash altogether) because a background task locks your database tables.
Multiple datetime columns
Created-at and updated-at speak for themselves. These are timestamps you want to display to the user in some fashion, and they’re too useful not to have. Deleted-at is for soft deletions (tombstones). Sometimes deletion is expensive and you want to just flag many items as deleted first and clean up asynchronously. When the data has actually been destroyed you can use ‘destroyed-at‘. You could delete the actual row from the database, but foreign keys could prevent that. In addition, if you want to show good error messages to users (“this item has been deleted”) it’s helps to keep the row around. Of course, you only need the metadata for this. The columns that contain actual user data you can overwrite when the user wants the data deleted.
If you provide some kind of full text search it helps to have an indexed-at column. You can use this to trigger re-indexing. You can use datetime columns like this for any kind of asynchronous update you want to run. Just select all rows where ‘indexed_at < updated_at‘ and do the necessary processing. Want to re-index a specific group? Just backdate the updated_at column and a background daemon will jump into action. Want to re-index 10 rows that didn’t get processed correctly the first time? It’s trivial. This is much less fragile than having some kind of message queue where you enqueue rows for additional work. A message queue can restart or get out of sync with the main SQL database really easily, but a simple datetime column works every time.
Append-only database tables
Dealing with immutable (meaning: unchanging) state is easy, and gives you version information for free. Being able to show users how their data has changed over time is a useful feature to add and it doesn’t cost anything. It’s just a matter of selecting the most recent row to get the most current data.
Storage is cheap and database engines can deal with large tables just fine. You can always fix performance problems when (and if!) they happen.
A surprise benefit is that caches automatically get invalidated if you use append-only strategies. You can’t have stale cashes for data that doesn’t exist yet. That’s a nice thing to get for free. (Assuming your app is read-heavy. For write-heavy apps this might actually be a disadvantage, because your cashes get invalidated prematurely.)
Multiple queries instead instead of complex queries
When you use an ORM to build your database queries you’ll get pretty naive queries by default. The ORM will happily select much more data than needed, or do thousands of small queries when one will do (see: N+1 problem). When you save objects most ORMs save the entire object back into the database, and not just the single property you’ve changed. ORMs aren’t sophisticated tools by any stretch of the imagination.
ORMs are really great at generating the most basic SQL queries, and we’ve learned that if you can rework your problem as a sequence of very basic queries you don’t end up fighting your ORM. I’ll give an example.
Suppose you want to generate a list of the 20 most popular books written by any of the top 3 most most popular authors. In Django ORM pseudocode:
popular_authors_ids = Books.sort(most_popular).limit(3).author_ids_only()
books_by_popular_authors = Books.filter(author__id__in=popular_authors_ids).sort(most_popular).limit(20)
The example is a bit contrived, but I hope it illustrates the point. By first selecting a bunch of ids that you need for the second query you end up with two very simple (and fast) database queries. Modern SQL databases are extremely powerful, and you can accomplish almost anything in a single query. But by splitting the work up in multiple queries you get three main benefits:
1) you know your ORM is going to generate reasonable SQL
2) you often get extra opportunities for caching the intermediate results
3) you can do additional filtering in Python, Ruby, NodeJS before you make another round-trip to the database to get your final results. This is often faster and easier than doing the same in SQL. Unicode handling in your database and in your target language are always going to subtly different, same with regular expressions. You’re better off using the database as dumb storage.
Extra JSON column
There are plenty of situations where you want to tag a couple of rows for whatever reason. Maybe you’re experimenting with a new feature. Maybe you need temporary storage for a migration. Maybe you need some logging for a hard to replicate bug. Being able to quickly serialize some metadata without having to add an extra column to a database is a big time-saver. You don’t even need to use the JSON serialization functionality in your database for this to be useful. Just being able to store a BLOB of data is where the real value is at.