You’re in the kitchen, preparing a meal. You’re in a hurry and you’re hungry. So you move fast. You grab a plate from a cupboard but you drop it and it shatters. You bend over to pick up some shards and as you get up you hit your head on the cupboard door you left open. You curse and rub your head. As you walk to the trash bin to throw away some of the broken ceramic you notice a pot starts boiling over. You rush back to the stove to turn off the heat and step on a shard you hadn’t picked up earlier. Now your foot is bleeding. You want to move the pot from the stove but there is no available counter space. You try to shove it on there anyway. A plate pushes into a cutting board that in turn pushes into a couple of glasses that were precariously placed right next to the sink. They fall in, and break.
It’s 2am and your phone buzzes. You see a notification your app is down. You’re confused and wonder if it’s a false alarm, but you look at your email and you see a bunch of angry messages. Oh crap. You’re exhausted and groggy, but you open your laptop look at some logs. 500 errors everywhere. You realize yesterday’s feature update is the problem. You revert the code but the database is now newer than the app expects, and the ORM doesn’t know how to deal with the new columns. Now your app service doesn’t start at all anymore. You decide to drop the columns you added yesterday, but in your haste you drop the wrong column from the database and now you’re in a lot of trouble. Do you restore the database from backups? How old are the backups, do you accept the data loss? How long does restoring from backups take anyway? Do you want to restore only the missing column from backups? How long will that take? How will you fix all data inconsistencies? It’s now 2:30am, you can barely think straight, everything is down, your database is broken, and all your options look terrible.

These are stories of cascading mistakes. With one unforced error after another even something small can turn into a major headache. But errors don’t have to compound like this. If you just take a moment to stop and think these problems almost disappear. Imagine this, instead:
You’re in the kitchen, preparing a meal. You drop a plate and it shatters. You stop and pause for a full 10 seconds. Ask yourself what your next action should be. Answer: turn off the stove. Close the cupboard. Move things out of the way you might bump into. Then slowly clean up all the shards. Then stop for 10 seconds and ask yourself if you forgot something else. You decide to free up counter space by loading up the dishwasher. Then you resume cooking. Total delay? Maybe 5 minutes. Really no big deal.
It’s 11 at night and you finish a feature you’ve been working on. You’ve tested it, and it looks OK. You decide it’s too late to push to production. Certainly too late to do a database migration. The next morning you make some coffee and launch your feature. Everything seems fine, but after a couple of minutes you notice something weird in the error logs. A customer emails asking if the service is down. Uh-oh. You think for a minute and decide not to do a full rollback — you already migrated the database after all — but decide instead to stub out the feature. You only have to change one line of code. You reply to the customer with an apology. You fire up your dev VM and fix the bug. Looks good. Push to production. Email the customer again to inform them the problem is resolved. You’re not happy about the bumpy release, but it really wasn’t so bad.
Everybody messes up sometime. We do, too. But we’ve never had significant downtime. Never lost customer data. Never had a database migration go badly wrong. In part it’s luck, but in part it’s because we try hard not to make bad things worse.
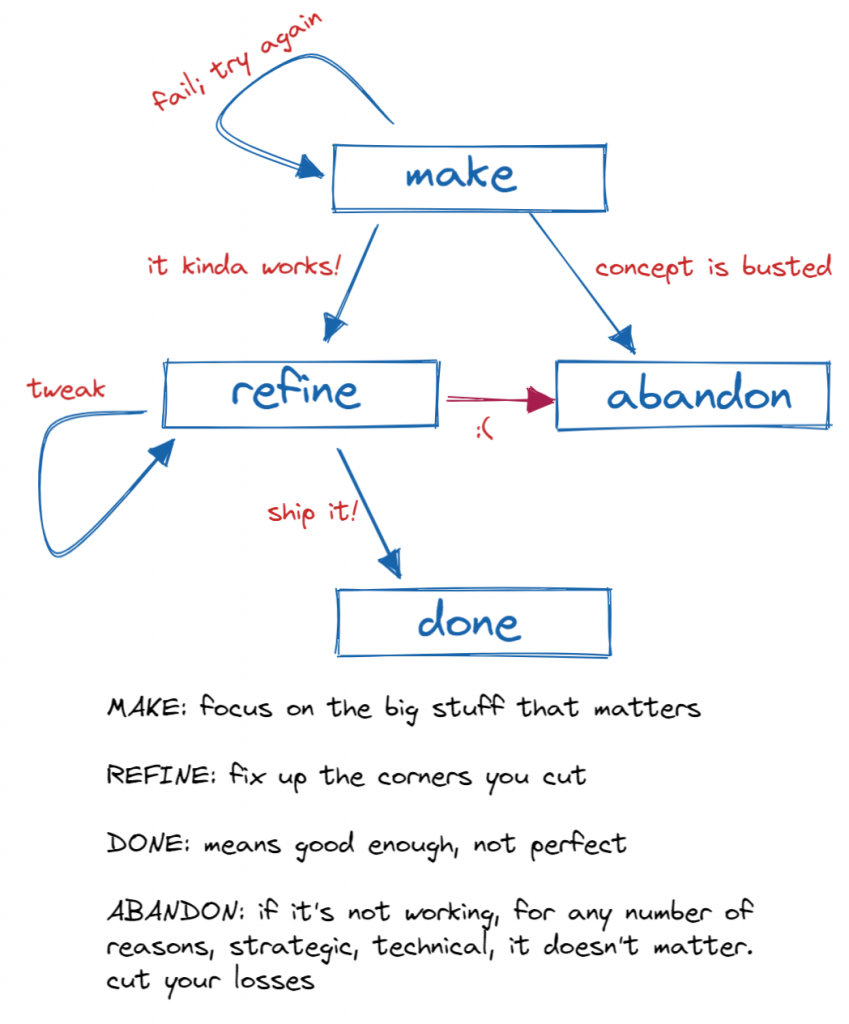
- when something breaks the first thing we do is stop and reflect
- then we diagnose
- then we stop and think how the fix might backfire on us
- then we ask ourselves if the fix is something we can roll back if need be
- then we stop again to think of an easier fix
- and only then do we apply the fix and test if it worked
Afterwards, we look for ways to eliminate the root cause of the problem. In the case above, it’s better to release the database migration and the feature separately. That way you can roll back a buggy feature without even thinking about it. Additionally, you want to feature flag complicated new features. That way you can gradually release features in production, and when trouble arises you can just turn the feature off. It takes basically no extra effort to take these precautions, and they’ll save you a lot of time and aggravation when you do something dumb like pushing to production right before you go to bed.
Some more lessons we learned the hard way about cascading problems:
- Don’t do routine server maintenance when you’re in a hurry, when tired or distracted. Regular maintenance should only take a few minutes, but you have to be prepared for things to go very wrong. If you do maintenance at 11pm you risk having to work throughout the night and that’s just asking for mistakes to compound. Maintenance work is easy, but you want to do it in the morning when you’ve had your coffee and you’re fresh.
- Don’t hit send on emails when you’re tired or annoyed. It’s OK to let a draft be a draft and you can hit send in the morning.
- Have local on-machine nightly backups of all config in
/etc/, deployment files, and everything you might break by accident. If you do something dumb and need to roll back in a hurry nothing beats being able to restore something withcp.
Config backups like these saved me twice: one time I deleted a bunch of files in /etc on a production server that were necessary for the system to boot. Figuring out which Debian packages corresponded to the missing files is tricky and besides, the package manager won’t run if /etc is missing. Print directory structure withfindfor /etc and /backup/etc. Usediffto see which files are missing.cp -arfto restore. Use the -a (archive) flag so you restore user, group, access permissions, and atime/mtime along with the files themselves.
Another time our JS compressor crashed and output partial data (on perfectly valid Javascript input no less) and there was no quick way to diagnose the problem. Our entire app was effectively down, so I needed a quick fix. It’s at those times that you really appreciate being able to restore last night’s JS bundle with a single copy command.
You need a simple backup system that works every time. Some people put /etc under version control, but this isn’t great because every server is at least somewhat unique (e.g. /etc/hosts, ip bindings). Nightly backups that allow you to simply diff and see what changed will never fail you. Many backup systems try to be too clever and you need to google command line options for basic operations. rdiff-backup gets almost everything right, although it breaks if you try to back up too much data. - Learn how to boot from a rescue environment and chroot into your system. chroot is basically magic. You can use this to fix your boot partition, broken packages, broken firewall/network config, mangled kernel installs and more.
We’ve only had to use this trick twice in the last 10 years. If a server doesn’t come back after a reboot and you start sweating, that’s when you need to keep your head cool and do some quick diagnostics. You can fail over, but failover is not without risks, and if you have no clue what happened you don’t know if the failover server(s) will collapse in the same way. Downtime sucks, but you always have 5 minutes to do some preliminary diagnostics and to think carefully about the next steps to take.
The lesson here is so simple and also one of the hardest ones for me personally to learn:
Slow down. Breathe. Don’t make things worse. Consider your options before acting.
Mistakes are unavoidable, but if you don’t let small mistakes cascade into something bigger you’ll notice you’ll spend very little of your time putting out fires.