
Anything that involves input or output should not just be considered unsafe but actively hostile, much like the critters in Australia. The programming languages and libraries you have to use are not designed with security in mind. This means you have to be totally paranoid about everything.
Let’s go over a few places where you have to deal with insecure defaults.
Zip archives
Suppose you add some backup feature to your app where users can download their files as a .zip, or maybe you let users upload a theme as a zip file. What could possibly go wrong?
Let’s start with the zip-slip vulnerability, allowing attackers to write anywhere on the system or remotely execute programs by creating specially crafted zip files with filenames like "../../evil.sh". This kind of attack made a big splash on the internet a couple of years ago. Many archive libraries were affected, and with those many libraries probably thousands of websites.
Most programmers will just use a zip library and not think hard about all the ways it can blow up in their face. That’s why libraries should have safe defaults. Relative paths should not be allowed by default. Funky filenames should not be allowed (e.g. files with characters in them, like backslashes, that are forbidden on other platforms). Because the libraries don’t do these checks for you, it’s up to you to reject everything that looks sus. Use of unicode should be highly restricted as well by default, more about that in a bit.
Zip exploits have happened before of course. Take Zip bombs for instance. Zip bombs are small files when zipped but get huge when decompressed. Zip bombs are at least 20 years old, and yet I don’t know of a single zip library for any programming language that forces the programmer to even think about the possibility that unzipping a small file can fill up all disk space on their server thereby crash the whole thing.
It’s pretty strange, when you think about it. In most cases the programmer knows, within an order of magnitude, what a reasonable unzip size is. It might be 100mb, it might be a gigabyte or more. Why not force the programmer to specify what the maximum unzip size should be?
When your unzip library doesn’t enforce limits you have to get creative. You can unzip to a separate unzip partition that is small. That way any unzip bombs will detonate harmlessly. But really, is it reasonable to go through this trouble?
It’s not just about disk space. You want limits for all system resources. How can you limit how much memory can be allocated during the unzip process? How can you limit how much wall time you’re willing to allocate? You can also use ulimit or a whole virtual machine, but that introduces a great deal of extra complexity and complexity is another source of bugs and security vulnerabilities.
Unicode
Unicode is the default for anything, and in the coming years we are going to see many creative unicode exploits. In the zip example above all filenames and file paths are unicode that can contain, among many other things, funky zero-width characters:
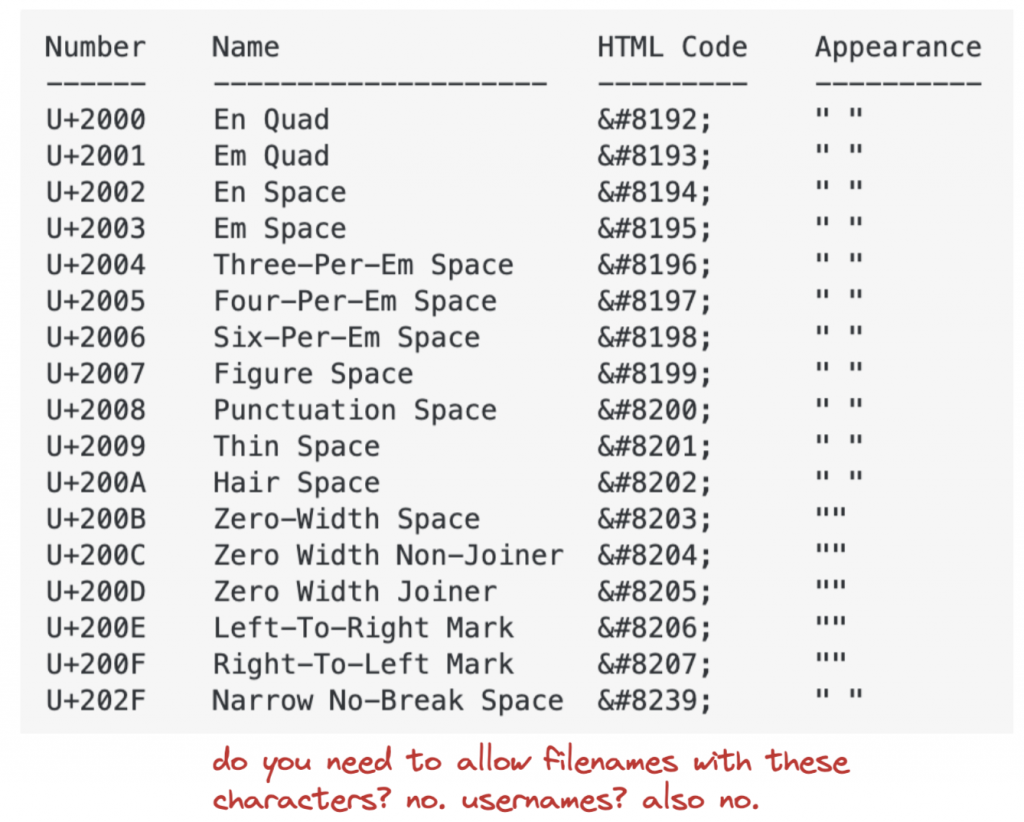
Unicode characters can trip you up in many ways. Suppose you have a webapp where people log in with a username. What could go wrong when you allow zero-width spaces inside usernames? It can go very wrong when you strip whitespace inconsistently.
For example, during registration you only strip ascii whitespace (space, tab, newline, etc) when checking if a user with that username already exists, but you strip all unicode whitespace when saving the user to the database. An attacker can exploit this collision by registering a new user with zero-width space added to the username of the victim. Two users rows will be returned by a login query like this:
SELECT * FROM users WHERE username = 'bobbytables' AND pw_hash = 123And databases typically return the oldest row first if no sort order is given, meaning the attacker has just logged on as the victim using his own password.
Layered paranoia helps here. First select the user row based on the username. If two rows are returned, bail. Only then validate whether that row matches the given password. You also want to use database uniqueness constraints so you can never end up with two rows in your user table with the same username.
XML – SVG
XML libraries support External Entities. Basically, you can upload an innocent looking XML file, and when parsed it includes a different file, like /etc/password, it can even allow full remote code execution.
A famous example here is ImageMagick, a popular graphics library used to create thumbnails for images. Upload a malicious image, BOOM, remote code execution (ImageTragick). This vulnerability existed for many years. ImageMagick was never intended to be used to process untrusted images passed through via web services. It’s just a product of a different era.
Any time you deal with XML files (or XML adjacent formats) you have to specifically check if the file format supports remote includes, and how the library deals with it. Even if remote includes just involve HTTP requests, and not access to your file system, you might still be in trouble. If you download the contents of a URL on behalf of a user the HTTP request is coming from inside your network. That means it’s behind your firewall, and if it’s a localhost request, it might be used to connect to internal diagnostics tools.
Maybe your http server runs a status package, like Apache Server Status. This page lists the most recent access log entries, and is accessible by default only from localhost. If a localhost access rule was your only layer of defense you’re now in trouble. Your access logs can contain sensitive info like single-use password-reset tokens.
User uploads malicious SVG file -> ImageMagick resolves External Entity and fetches Access Log via HTTP -> Renders to PNG and displays to user as thumbnail.
It’s hard to predict in advance how innocent features can be combined into critical security failures. Layers of defense help here. Limit what kind of image files can be uploaded. Google for best security practices for the libraries you use. Most foot-guns are well known years before the big exploits hit the mainstream.
Regular expressions
Regular expressions are great, but it’s still too easy to introduce serious denial of service vulnerabilities in your code by being slightly careless. We’ve been burned by this a few times. A simple regular expression that caused no trouble for years suddenly eats gigabytes of memory. Because of the memory pressure the linux OOM killer decides to kill memcached or the SQL server and then everything grinds to a halt.
What kind of regular expression can cause that kind of mayhem? Easy, one that looks like this: (a|aa)*c
A regular expression by default tries to find the longest match. This can result in exponential backtracking. For more reading see ReDoS on wikipedia. If you make it a habit to look for shortest matches, using *? instead of * you’re much less likely to write an exploitable regular expression. If you also validate input length and keep your regular expressions short and simple you should be fine.
Regular expressions are incredibly useful. Still, regular expression engines would be way more useful if you could give them a time and memory budget. If a regular expression is intended to take a few milliseconds I want an exception thrown when it takes 2 seconds instead. If a regular expression starts allocating memory I want to know about it, before it turns into a big problem.
Working towards good defaults
Take this gem of a comment from the golang zip library:
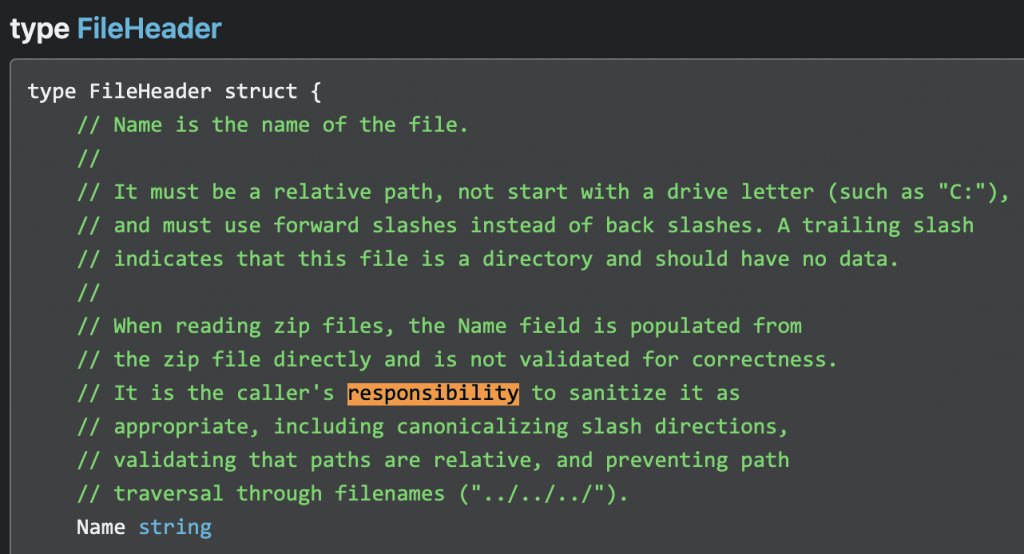
Instead of validating input and providing a safe API by default the library just pushes the responsibility onto the user (the programmer in this case) who is likely to be either too inexperienced or too pressured by deadlines to take all the necessary precautions.
The point here isn’t to suggest Go is bad, but that times have changed and most software written today has to survive in a hostile environment. The only way forward is to move to secure defaults everywhere, with flags for unsafe mode for those cases where you trust the input. It will take long time before we get there, and until then you need many layers of security.